RDBMS에서의 Foreign key(외래키)에 대한 고찰 (어쩌다가 우리는 FK를 쓰지 않는가?)
최근 RDBMS환경에서 일일 1,000만개 이상의 데이터가 지속적으로
insert, delete되며 데이터최신화를 위한 개발환경을 겪으면서 외래키에 대한 생각을 끄적여봄.
결론부터 이야기하자면
"아무리 작은 프로젝트라도 FK를 강제하는것이 좋다"
실무자들은 다 알겠지만,
Foreign key는 간략하게 FK라고 칭하겠음...
솔직히 대부분의 프로젝트에서 SI든 자체플젝이든 FK를 사용하지 않는것이 현실임.
그리고 많은 개발자들이 분명 배울때는 FK를 걸어야된다는 걸 알고 있지만
개발의 용이성(?)과 원활한 DB설계변경을 위해 FK를 걸지 않는 것 또한 현실임.
개발자들이 FK를 설정하지 않는 이유는 대체적으로 다음과 같다.
1. DBA의 부재
프로젝트에서 실질적인 DBA가 없어서 개발자들이 사실상 DBA역할까지 해야하는 경우가 많고 그런 개발자들이 DBA가 해야되는 모든 역할을 기대하기 어려움.
2. FK에 따른 데이터 소실우려
Sub table을 구성하다보면 여기저기 FK를 연결하는 경우가 많은데 복잡구리하게 구성된 Parent table 중에서 단 하나의 데이터만이라도 수정/변경되면 의도치 못한 Sub table의 데이터가 변경되는 경우를 두려워함.(우리의 데이터는 소중하니깐)
3. 임의의 데이터 삽입의 번거로움
Sub table에서 임의 데이터를 삽입코자 할때 CASCADE 설정시 반드시 Parent table도 추가해줘야되는 그지같은 상황 때문에.(우린 자유로운 영혼이라규!!!)
4. Insert Query의 속도 저하
FK가 설정된 table에서 Insert Query시 약간의 속도저하가 있다고 함.(사실 별 차이 못느끼겠음)
5. FK 설정법을 모름
생각보다 최근 신입개발자들한테 물어보면 FK설정법을 아예 모르는 경우가 왕왕있음.
RDBMS의 물리적인 FK설정을 하지 않음에도 프로그램 로직단에서 충분히 FK처럼(?)구현도 가능하고 Join역시 가능한 것도 사실임.
지금부터 예제를 통해 왜 우리가 FK를 써야되는지를 설명하도록 한다.
다음은 아주아주 심플한 예제용 ERD diagram 이다.
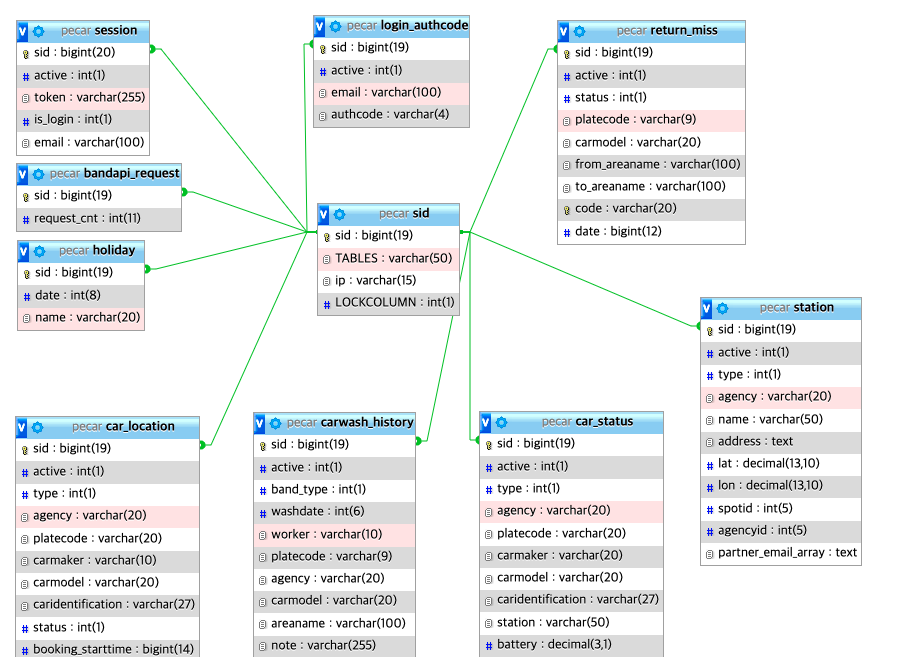
일반적인 환경일수도 아닐수도 있지만, 이 ERD를 보면 모든 테이블들이 sid라는 테이블을 FK로 연결되어있다.
각 테이블의 sid 데이터들은 절대적으로 유일무이한 값이 되는 일종의 Super key로 구성되어 있다.


이렇게 설계하는 이유는 데이터정합성과 super key 하나만으로 CRUD추적성을 제공하기 위함이다.
insert시 insert를 진행하고자 하는 테이블 이외에 추가적으로 동일의 키를 sid 테이블에 넣어줘야하는 불편함이 있지만,
sid 테이블에서 해당 key가 저장된 테이블을 저장하고 있음으로 key값 하나만으로 select, update, delete가 굉장히 쉬워진다.
이런 설계 방식은 외부서비스와의 API 연동 시 더욱 빛을 발한다.
예제에서는 숫자로만 구성된 19자리의 시간정보로만 사용하지만 UUID나 Hashing 값을 이용하는 방법도 있다.
범용 고유 식별자 - 위키백과, 우리 모두의 백과사전
범용 고유 식별자(汎用固有識別子, 영어: universally unique identifier, UUID)는 소프트웨어 구축에 쓰이는 식별자 표준으로, 개방 소프트웨어 재단(OSF)이 분산 컴퓨팅 환경(DCE)의 일부로 표준화하였다. U
ko.wikipedia.org
FK를 사용하지 않을때 대용량 insert 과정에서의 문제점.
논리적인(?)방법으로 프로그램코드상으로 FK를 운영할 경우, 해당 key가 자신테이블, 그리고 부모테이블에 존재하는지를 확인하고,
중복되는 데이터를 늘 checking 해야한다.

ERD상으로는 부모테이블이 sid임으로 super key를 생성한뒤, sid에 고유값인지 select후 insert를 한다.
이후 insert하고자하는 자신테이블에도 동일한 super key를 insert하게 된다.
아무 문제없이 잘된다.
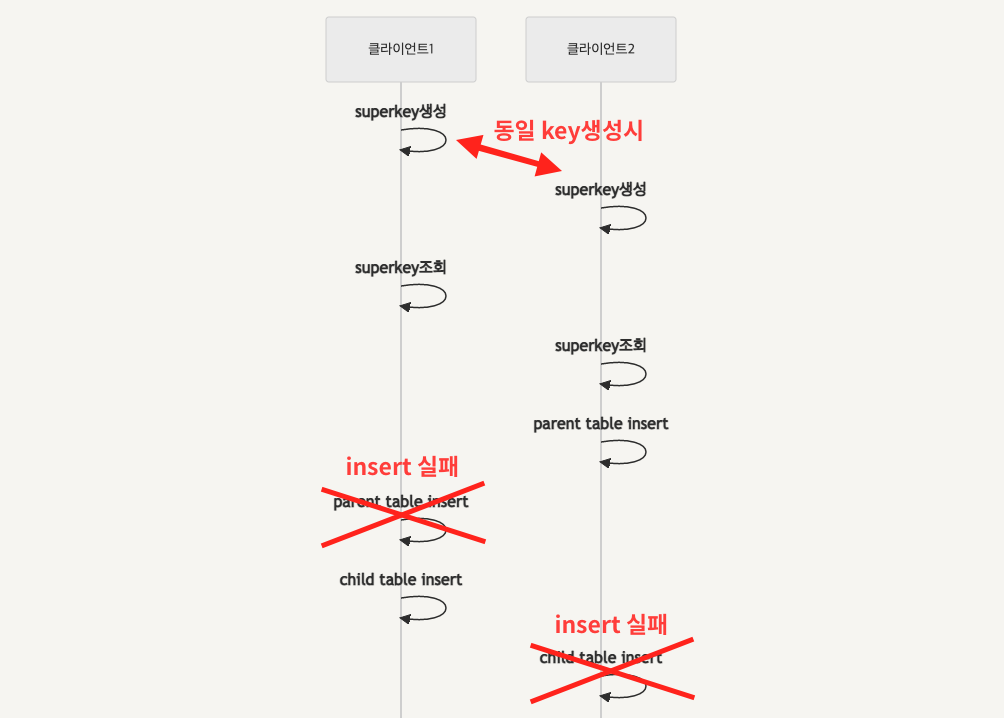
문제는 대용량 insert가 발생되는 상황은 우리가 상상하는것과 다르게 동작할 수 있다.
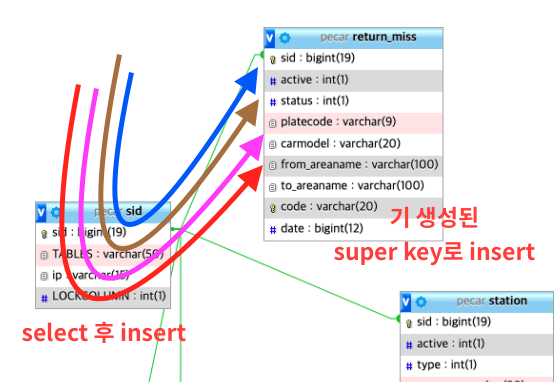
분명, super key를 생성해서 부모테이블에 해당 key가 없다고 해서 자신테이블에 동일한 super key를 insert 하면 자신테이블에 중복된 key가 존재하는 경우가 발생할 수 있다. 각각의 테이블마다 Primery key를 설정하여 중복을 방지하는것도 방법이지만, PK를 설정할 경우 중복된 key는 사라지겠지만, 중복된 key를 갖는 insert 데이터를 소실할 수도 있다.
이런 원인이 발생되는 이유는 부모테이블과 자식테이블간 key가 매칭이 안되어있기 때문이다.
super key를 생성해서 부모테이블에 해당 key가 없다고 하는것은 언제나 애플리케이션의 판단일 뿐이고, 실제로 DB에 insert되기 전까지는 중복될 수 있다는 이야기이다.
이러한 현상은 단순 insert로직뿐만 아니라 insert, delete, update등 데이터가 입력,수정,삭제등 데이터최신화가 반복되어야하는 대부분의 로직에서 문제를 엄청나게 큰 발생시킨다.
다중쿼리 및 트랜잭션을 통해 이러한 문제를 해결할 수 있는 하나의 방편이 될 수 있지만,
다중쿼리에 따른 추가적인 injection처리는 논외로 한다고 해도,
단일 쿼리별 예외처리의 문제를 해결할 솔루션을 고민해봐야하며,
트랜잭션에 따른 동시성 제어 또한 생각해볼 문제이다.
(겨우 일일 1000만개 데이터에서 벌써부터 트랜잭션제어를 하기엔 아까운것은 사실)

아무리 순차처리가 가능한 애플리케이션과 순차처리가 가능하게끔 프로그램을 짜도, 문제는 애플리케이션의 하위계층인 OS는 순차처리를 보장하지 않으며, 특히 Multi-connection을 제공해야하는 서버프로그램일수록 connection마다의 정확한 순차처리를 기대할 수 없다.
클라이언트의 요청 순서대로 처리한다는것은 단순히 우리들의 바램일뿐....
FK를 설정하는 방법
다음은 FK를 설정하는 방법이다.
//단순 FK설정
ALTER TABLE `자식테이블`
ADD CONSTRAINT `별명`
FOREIGN KEY (`자식칼럼명`)
REFERENCES `부모테이블`(`부모칼럼명`);
//예시
ALTER TABLE `holiday`
ADD CONSTRAINT `FK_holiday`
FOREIGN KEY (`sid`)
REFERENCES `sid`(`sid`);
제약조건을 통해 수정/삭제에 대한 부모테이블과 자식테이블간 데이터의 관계성을 유지시킬 수 있다.
//CASCADE예시
ALTER TABLE `holiday`
ADD CONSTRAINT `FK_holiday`
FOREIGN KEY (`sid`)
REFERENCES `sid`(`sid`)
ON DELETE CASCADE
ON UPDATE CASCADE;| FK설정시 제약조건 옵션 | 설명 | 종속성 |
| CASCADE | 부모테이블의 데이터가 수정/삭제 시 자식테이블의 데이터도 함께 수정/삭제된다. | 부모테이블에 종속 |
| RESTRICT | 자식테이블의 데이터가 존재하면, 부모테이블을 수정/삭제할 수 없다. | 자식테이블에 종속 |
| NO ACTION | 부모테이블의 데이터가 수정/삭제해도 자식테이블은 별다른 Action을 하지 않는다. | 종속강제 X |